 |
|
A Tutorial on XMorph
Flexible Querying for XML |
| Home | |
| Tutorial | |
| Demo | |
| Download | |
| Publications | |
| Curtis Dyreson | |
| Home | |
| Publications | |
| Projects | |
| Software | |
| Demos | |
| Teaching | |
| Contact me | |
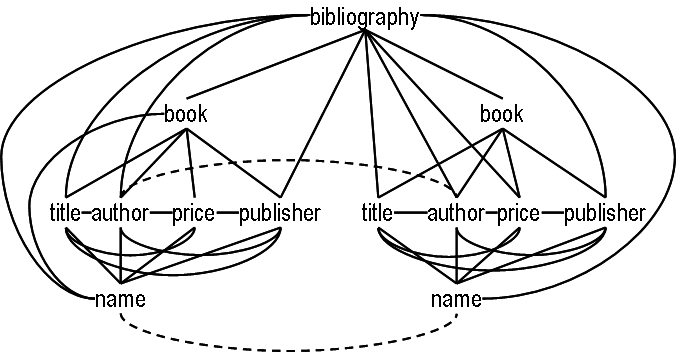
This section gives a short tutorial on XMorph through a series of examples of increasing complexity. The ANTLR syntax for XMorph is available. The examples in this tutorial will transform the data about books written by E. F. Codd shown below.

Though database query languages tend to be declarative rather than functional, XMorph is a functional query language (i.e., similar to a query algebra rather than a query calculus). The primary function in XMorph is a morph, which places children below a parent in the result. The parameter of the morph function is a pattern, which specifies the structure of the result. Below is an example of a morph.
List titles by author: MORPH author [ name title ]To run the tutorial queries, use the demo code.
The query lists the titles written by each author extracted from a collection of book data. The pattern specifies that <title> and <name> elements are placed as children of <author> elements. Only <title> and <name> elements that are closest to an <author> element are placed within that <author>. The notion of closeness, which forms the core semantics for XMorph, is explained in the XMorph publications, but intuitively the idea is that authors are closely related to the titles of their own books and articles (and their own names), but not close to titles written by others (or the names of others).
A morph can be restricted to select individual authors. Suppose we want only the titles by the author E. F. Codd. Then we can use the query given in below which selects <author> elements where the value of the element is 'E.F. Codd'.
List titles only for the author named 'E. F. Codd': MORPH author [ name, WHERE value == 'E.F. Codd' title ]
The result is the same as that above since only E. F. Codd has authored books in the source data.
There may be duplicate authors in the data, but authors can be grouped to eliminate the duplicates. The query given below shows an example that consolidates titles under a single name using a 'group' modifier for the author's name.
List titles grouped by author name: MORPH name, GROUP [ title [ book, HIDE ] ]
Modifiers are listed after a label, separated by commas. The group modifier uses the default, persistent grouping for author (e.g., author is grouped by its 'key' as specified by the data's schema, or by the distinct-values function for a schema-less data collection). Authors could also be dynamically grouped during query evaluation, by specifying a grouping pattern. E. F. Codd wrote both books and articles, and we may want to select only book titles. In the query given in below, <title> elements closest to a <book> element are selected but books are hidden in the output; a <book> is only used to find a closely-related <title>. The result is the same as that shown above since the data has only <book>s.
List book titles by E. F. Codd: MORPH name, GROUP, WHERE value == 'E.F. Codd' [ title [ book, HIDE ] ]
Though XMorph assumes that a user is familiar with the vocabulary of the data, it also has a translate function to automate translation of a query or its result into the terms desired by a user. The translation can be specified before a morph, with the output of the translation being piped into the morph, as shown below, or after a morph, in which case the output of the morph is piped into a translate function.
Translate author to writer: TRANSLATE author -> writer | MORPH writer [ name, WHERE value == 'E.F. Codd' title [ book, HIDE ] ]
To this point, the descriptions of the queries have avoided describing the shape of the input, that is, the same query could be applied to data in a variety of hierarchies. Moreover each query, when applied to the same data in different hierarchies will produce the same output. The only hierarchy that the user needs to specify is that of the output. To illustrate this, consider the query shown below. The pipe operator, '|', is used to compose morphs.
Morphing a morph: COMPOSE MORPH (GROUP publisher) [ title [ author [ name ] ] ] WITH MORPH author [ name title ]To run the tutorial queries, use the demo code.
The query applies a morph to the result of a morph. The first morph produces a hierarchy which lists the titles published in each year and within each title the authors for that title. The second morph is a transformation previously given.
XMorph also supports mutation of the data's hierarchy. A mutation is like a morph in that it changes the shape of the hierarchy; but unlike a morph, the entire hierarchy is implicitly involved. A mutation is given in below.
Mutating: MUTATE author [ publisher (CLONE title) ]To run the tutorial queries, use the demo code.
The mutation explicitly lists only three types, but it outputs the entire hierarchy, with two mutations. First it moves <publisher> elements to within the closest <author> elements, and second, it clones <title> elements to also place them under the closest <author> (the un-cloned <title> elements will remain in place). The rest of the hierarchy is not changed.
These examples show a few of the uses of XMorph and illustrate its most important design feature: shape polymorphism. In a shape polymorphic query language users specify only what they want as output. A query adapts to the shape of the input data to produce the desired output. In XMorph, this adaptation is based on the notion of closeness.
Curtis E. Dyreson © 2013. All rights reserved.